
Wstępne przetwarzanie danych
Redukcja liczby cech
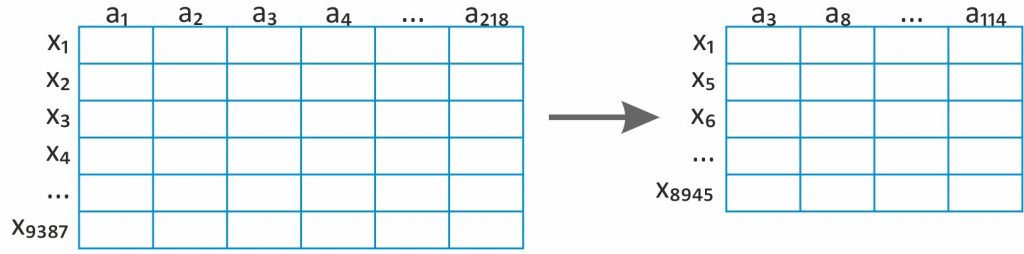
W przypadku danych, których rozmiar jest znaczny, istotnym krokiem przetwarzania wstępnego jest ograniczenie liczby cech (kolumn) przekazywanych do eksploracji. Zadanie to nosi nazwę redukcji liczby cech i może być wykonane w dwojaki sposób. Pierwszy z nich, zwany selekcją cech, polega na eliminacji nadmiarowych, mało istotnych cech (tzw. cech redundantnych). Drugi zaś, zwany ekstrakcją cech, polega na agregacji cech w mniej liczny zbiór nowych cech.
W pierwszym przypadku poszukiwany jest minimalny zbiór oryginalnych cech reprezentujący wyjściowy zbiór danych w możliwie najwierniejszy sposób. W praktyce oznacza to poszukiwanie pewnego podzbioru cech. Jako że dla n cech całkowita liczba możliwych ich podzbiorów wynosi 2n, przeszukiwanie wyczerpujące jest zwykle mało efektywne, a czasem wręcz niemożliwe. Dlatego stosuje się metody heurystyczne, bazujące m.in. na miarach prawdopodobieństwa (np. analiza kowariancji, korelacji), miarach ilości informacji (wyrażanej m.in. entropią) czy z wykorzystaniem metod inteligencji obliczeniowej, takich jak np. algorytmy genetyczne czy drzewa decyzyjne.
W przypadku ekstrakcji zbiór analizowanych cech jest ograniczany poprzez tworzenie nowych cech będących kombinacją cech wyjściowych. Na przykład zamiast używać dwóch cech takich jak długość i szerokość można wprowadzić nową cechę – pole powierzchni, będącą ich kombinacją, w tym przypadku iloczynem z wagami równymi 1. Nie zawsze jednak jesteśmy w stanie utworzyć cechy mające – tak jak w powyższym przykładzie – interpretację. Niemniej jednak zasada jest podobna. W tym zakresie najbardziej popularnymi metodami są analiza składowych głównych PCA (Principal Component Analysis) oraz analiza czynnikowa. Zwykle jednak cechy te nie mają interpretacji, a wybór sposobu redukcji liczby cech może być podyktowany niekiedy właśnie taką koniecznością.
Redukcja liczby cech, często oprócz usunięcia cech nieniosących istotnych informacji i zmniejszenia złożoności obliczeniowej algorytmów eksploracji, ma jeszcze kilka innych zalet. Ułatwia między innymi zrozumienie wyników ostatecznej analizy oraz zapobiega nadmiernemu dopasowaniu opracowanych modeli do danych.
Galeria






Co tydzień otrzymaj od nas porządną dawkę wiedzy o branży przemysłowej!



































