
Wstępne przetwarzanie danych
Zbiory danych mogą stać się cennym źródłem wiedzy. Aby tak się jednak stało, musimy we właściwy sposób podejść do ich analizy. Proces analizy danych składa się z kilku etapów (opisanych w nr. 1/2020 „Utrzymania Ruchu” w artykule Analiza dużych zbiorów danych). Kluczowym etapem jest etap wstępnego przetwarzania danych, który bezpośrednio poprzedza etap eksploracji i jest często etapem najbardziej pracochłonnym.
Właściwie przeprowadzone wstępne przetwarzanie nie tylko usprawnia proces eksploracji, ale też w znaczący sposób poprawia możliwości interpretacji uzyskanych wyników.
Wstępne przetwarzanie danych składa się z kilku kroków, takich jak:
- selekcja danych,
- czyszczenie danych,
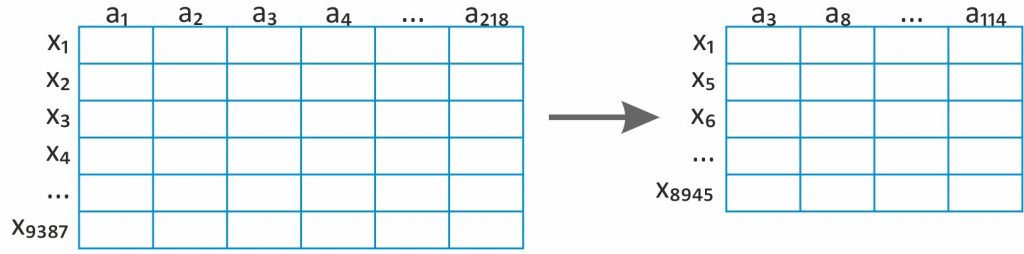
- redukcja liczby cech,
- transformacja,
- dyskretyzacja wartości.
Nie zawsze wszystkie kroki są wymagane. Zależy to od jakości danych, od celu, jaki chcemy osiągnąć, ale też bezpośrednio od metod eksploracji, których zamierzamy użyć.
Selekcja danych
Gromadzona jest ogromna liczba danych. W wielu przypadkach część z nich albo nie ma związku z celem prowadzonych analiz, albo jest redundantna (nadmiarowa), czyli niesie taką samą informację. Eliminacja choćby części danych i wybór jedynie istotnych pozwalają nie tylko zmniejszyć nakład pracy w dalszych krokach wstępnego przetwarzania, ale w znaczący sposób mogą wpłynąć na wydajność procesu eksploracji i jakość uzyskiwanych wyników. Tego typu selekcja najczęściej dokonywana jest ręcznie, a dokładna znajomość analizowanego procesu i pełne zrozumienie gromadzonych danych są w tym przypadku niezwykle istotne.
Czyszczenie danych
Rzeczywiste dane prawie zawsze są niedoskonałe. Najczęstszymi niedoskonałościami są pojawiające się braki wartości oraz wartości błędne. Zarówno problem braków, jak i błędnych wartości może być związany m.in. z zakłóceniami w transmisji danych, ze zmianami warunków pomiarów lub z awariami czujników czy torów pomiarowych. Konieczne w tym przypadku staje się wyczyszczenie danych (rys. 1).
Generalnie problem ten można rozwiązać na dwa sposoby:
- poprzez odrzucenie z dalszej analizy danych zawierających braki,
- poprzez uzupełnienie brakujących wartości.
Usuwanie braków może się odbywać poprzez usuwanie całych rekordów (co jest dopuszczalne z reguły jedynie wówczas, gdy braki dotyczą stosunkowo niewielkiej liczby przypadków i mamy pewność, że nie będzie to prowadziło do uzyskania tendencyjnych wyników analizy) bądź też poprzez usuwanie wybranych zmiennych (kolumn), gdy to głównie one zawierają braki. Uzupełnienie wartości, zwane często imputacją, oznacza zastąpienie wartości brakującej, w zależności od przypadku, np. wartością średnią danej zmiennej lub medianą, ostatnią zaobserwowaną wartością, wartością określoną na podstawie przypadku „podobnego” lub wartością wyliczoną na podstawie modelu regresji zbudowanego na wartościach pozostałych zmiennych.
W ten sam sposób można postępować przy eliminowaniu błędnych danych. Czyszczenie danych może obejmować również inne działania, takie jak np. wykrywanie i ewentualne usuwanie obserwacji odstających. Zakres prowadzonych w tym kroku czynności zależy m.in. od stosowanych w dalszym etapie metod eksploracji danych. Niektóre z nich (jak np. metoda drzew decyzyjnych) dobrze radzą sobie z danymi, w których występują braki, inne zaś nie dopuszczają takiej możliwości.
Opisane działania nie wyczerpują wszystkich możliwości. W konkretnych przypadkach konieczne może być sięgnięcie do bardziej zaawansowanych metod opisanych w specjalistycznej literaturze.
Galeria






Co tydzień otrzymaj od nas porządną dawkę wiedzy o branży przemysłowej!



































